Cloudflare 'super bot fight' come farne a meno (parte 2)
Bentornati!
Come dicevamo nel post precedente, cloudflare ci offre la possibilità di schermare il nostro dominio dai bot fastidiosi o decisamente malevoli.
Il problema principale è che abbiamo una perdita di velocità di caricamento, perchè il sistema deve fare una serie di controlli aggiuntivi, per schermarci da questi aggressori.
I controlli generalmente avvengono in background, in maniera trasparente all’utente, che quasi non si accorge di quello che sta succedendo, tranne quando viene visualizzato un captcha che chiede di riconoscere navi, idranti, case, biciclette, ecc.
Qua c’è una spiegazione più tecnica di cloudflare, se vi interessa.
…ma è comunque una seccatura
Oltre al fatto del ritardo, che generalmente possiamo notare e misurare solo con degli strumenti come il Google Pagespeed se pensiamo al disturbo che crea agli utenti questa caratteristica, dovremmo porci in un’ottica professionale.
Quanti potenziali clienti/contatti/fatturato sto perdendo ?
Chiaro che se avete un sito hobbistico, non vi ponete il problema, ma se siete arrivati a questo blog partendo da linkedin o twitter, probabilmente avete un interesse lavorativo.
C’è un secondo problema di fondo: con questa modalità di mettiamo interamente nelle mani di Cloudflare. Il rischio che ci possano essere dei falsi positivi non è nullo, per quanto storicamente non mi sono ancora capitati casi dei grandi motori di ricerca o dei social media, che siano stati “rifiutati” dal sistema.
Posto il problema, spieghiamo la soluzione
Per prima cosa, se l’abbiamo attivato, disattiviamo l’opzione del super fight.

E come seconda cosa andiamo nel WAF, ovvero “web application firewall”, che è all’interno della voce di menù della Security.
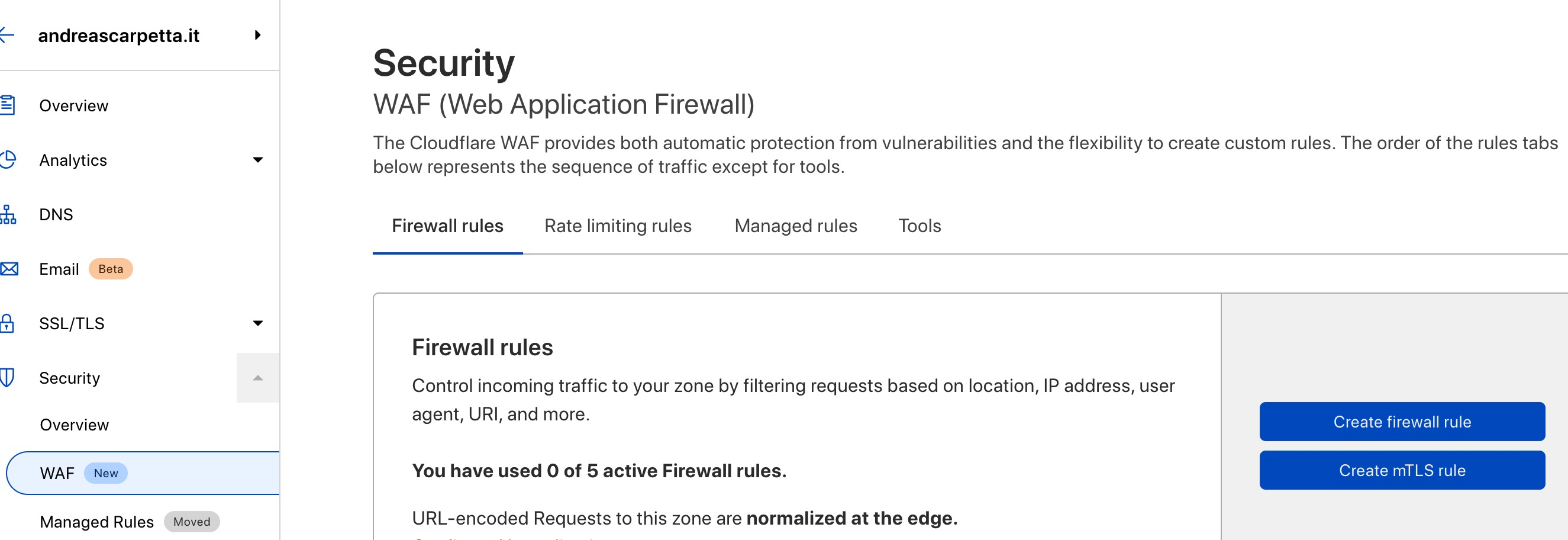
Cosa fa il WAF
nella versione gratuita di cloudflare abbiamo cinque regole del firewall da applicare ad ogni dominio inserito. Nelle versioni a pagamento questo limite sale a 20, 100 o 1000.
Fortunatamente queste regole sono abbastanza flessibili, per cui possiamo fare un uso ragionato che copre diversi casi.
come funzionano ?
In pratica è abbastanza semplice: viene definita una regola. Se questa regola si avvera, viene fatta una azione.
Partiamo dalle azioni
Se scatta la regola cloudflare può fare:
- Blocca accesso (il client non vede nemmeno il sito)
- Ammetti accesso (normale)
- Ignora e passa alla regola dopo (ottimo per fare controlli concatenati)
- Lancia una sfida javascript (che esploriamo nella sezione successiva)
- Gestisci la sfida in automatico
Che cosa sono queste sfide (challenge)?
Cloudflare quando avviene una connessione, lancia una serie di “test” per capire se il client che si sta connettendo è un vero browser o è soltanto un processo che sta simulando un accesso.
Le sfide consentono di identificare il processo, perchè moltissimi programmi di questo genere non hanno un interprete javascript in grado di risolvere le sfide, quindi vengono rimbalzati.
La sfida “gestita” è ad un livello ulteriore: perchè se il sistema non è convinto (e potrebbe usare diversi parametri), propone una catena di sfide fino ad arrivare alla pressione di un pulsante e in ultima analisi al captcha.
Chiaramente solo una persona reale o un sistema di “captcha breaking” possono superare questi test, ma c’è un costo di tempo o monetario, per cui va considerato il rapporto costo/beneficio: se è semplicemente un ladruncolo che vuole arraffare i dati di un sito, probabilmente si ferma qua. Se è un assassino professionista che deve riscuotere la taglia sulla tua testa, non è sufficiente a fermarlo… ma se hai lasciato dati personali sul tuo sito, probabilmente hai fatto delle scelte di vita sbagliate.
Molto interessante, ma cosa cambia rispetto al super bot fight?
Ottima domanda, se te la sei posta.
Il super bot fight, viene fatto su TUTTE le visite al sito. Crawlers dei motori, Crawlers dei social media, Crawlers degli strumenti seo, utenti, scrapers e bot di ogni tipo non inclusi nelle categorie precedenti.
Ma noi con il WAF possiamo limitare i controlli solo ad una platea di nostra scelta: le regole di cui parlavamo sopra.
Come sono fatte le regole
Ogni regola è divisa in tre parti:
-
il “campo da analizzare” (field)
-
la condizione (Operator)
-
il valore da analizzare (Value)
Se avete delle basi di informatica è equivalente ad un costrutto if->then , cioè “Se capita questo caso specifico, fai questa azione.”
Bene.
Il nostro campo da analizzare è decisamente variopinto:
- ASNUM: è un numero che identifica il “gruppo geografico” di un indirizzo IP
- COUNTRY: La nazione di provenienza dell’indirizzo IP
- CONTINENT: il continente dell’indirizzo IP
- HOSTNAME: il “nome” del computer che si sta collegando
- IP: l’indirizzo ip estresso in triplette quindi 127.127.127.127
- REFERRER: il nome del sito che ha mandato la visita, questo capita quando si clicca su link di qualsiasi tipo verso un sito esterno.
- il PERCORSO RICHIESTO: che può essere completo (https://www.sito.com/qualcosa?parametro=1) o in solo parziale (/qualcosa) o solo i parametri (?parametro=1
- lo USER AGENT: il nome e la versione del client che si sta collegando (chrome, firefox, o altro ancora. Ne esistono 200 milioni.) Chiaramente può essere “falsificato” da attori malevoli che molto spesso fanno finta di essere Googlebot.
…e qualche altro campo che non menziono perchè sono estremamente tecnici ma che potete trovare su questa pagina ufficiale.
Scelto il campo da analizzare, passiamo alla condizione.
In questo caso abbiamo poche scelte ma molto chiare:
- è uguale a…
- non è uguale a…
- è minore di…
- è maggiore di…
- contiene la parola…
- rispetta la regola regex…
- è incluso in un elenco…
Alcune di queste condizioni si applicano solo a numeri, alcuni sono a testi, altre ad entrambi. La tabella completa è disponibile in questa pagina ufficiale.
nb: la regex è potentissima, ma è disponibile solo con un account Business o Enterprise.
Infine il valore è semplicemente un campo di testo che decidiamo noi cosa scriverci dentro o scegliamo da un elenco proposto da cloudlare.
C’è ancora un elemento opzionale, ma per non mettere troppa carne al fuoco, ne parliamo dopo. Prima di farvi scappare da questa pagina, passiamo alla pratica…
Facciamo un esempio pratico
Diciamo che io voglio fare una regola che dice
- “Tutti i visitatori che arrivano dalla Russia devono essere bloccati.”
in questo caso gli elementi sono:
- Provenienza: nazione (Country)
- la condizione diventa “è uguale a (equals)”
- il valore è “Russia (Russian Federation)” (scelto dall’elenco)
- l’azione è “blocca”


Dal momento in cui clicco “Deploy”, tutti i visitatori il cui IP è riconducibile alla federazione Russa, vengono bloccati.
Questo chiaramente non impedisce ad un utente scaltro di usare una VPN e mascherare il suo ip come se fosse in un’altra nazione, ma per quanto riguarda gli automatismi è meno probabile che accada. Ma non è così raro, ci sono servizi che vendono l’accesso tramite proxy nazionali a rotazione, che quindi hanno a disposizione centinaia di ip da utilizzare per mascherare le connessioni originali.
Quindi il gioco si fa duro
Supponiamo di aver delimitato l’accesso geograficamente, perchè il mio sito si rivolge solo all’italia.
Per essere tranchant, escludo i continenti che non mi interessano e lascio solo l’Europa e l’America (da cui provengono probabilmente Googlebot e Bingbot).
con la condizione “IS IN...” oppure “IS NOT IN…” posso fare selezioni multiple.

nb: il continente TOR non esiste, si tratta degli utenti connessi tramite il TOR network.
Facendo così ho iniziato a scremare un po’ di rompiscatole, ma è solo la punta dell’iceberg, perchè tra Europa e America, ci sono una serie di provider che permettono agli utenti di comprare server virtuali con i quale poi fare “attacchi automatici”. (parlare di attacco è un po’ una esagerazione, non si tratta quasi mai del cosidetto “Denial of service” che abbatte i server. Nella maggior parte dei casi si tratta di sistemi per fare scraping selvaggio dei dati altrui.)
A questo punto, diciamo che ho uno dei CMS più (ab)usati al mondo, WORDPRESS e quindi la maggior parte degli hacker di fascia bassa, cerca di violarne gli accessi continuamente.
Posso proteggermi con questo sistema? decisamente si!
bloccare un attacco classico
Un tentativo di hackeraggio classico (da poveretti del web) è quello che che cerca di andare sulla pagina /wp-login.php per cercare di fare un attacco di “forza bruta” usando un nome utente standard e una serie di password comuni.
Come mi accorgo di questo? Se ho attivato la modalità del super bot fight troverò un elenco di risultati nella pagina Security/Overwiew

E se clicco su una riga posso vedere il dettaglio:

Fortunatamente questo specifico blog non usa wordpress, ma questo non impedisce a queste canaglie di provarci.
Quindi a questo punto creo una regola che chiunque cerchi di accedere a questo percorso “/wp-login.php” viene testato a morte ed eventualmente deve risolvere un captcha.

Ma se devo accederci io ?
Chiaramente a questo punto viene spontaneo sbuffare e dire
“che palle, che devo magari mettere il captcha pure io!”
- Premessa 1: non è detto, perchè se accediamo da una connessione normale, con un browser normale, probabilmente il captcha nemmeno salta fuori.
- Premessa 2: possiamo auto-escluderci dai controlli.
Infatti ogni regola ha la possiblità di aggiungere delle condizioni aggiuntive , che sono operatori “logici” : ossia “e” oppure “o”.
Senza entrare nell’informatica avanzata con “e” posso mettere due condizioni che devono essere entrambe “vere”, “o” basta che una sola sia “vera”.
se “è nero e “miagola” è un “gatto nero”, se “è nero” o “miagola” potrebbe essere un corvo o un gatto.
Ok fin qua ?
Cloudflare ci consente di aggiungere tutti gli operatori logici che vogliamo… o meglio io per ora sono arrivato a QUINDICI operatori e tutto funziona ancora bene…
Quindi facciamo un’ipotesi:
io vivo in Italia, quindi quando accedo a wp-login.php i controlli non devono esserci.
Lo possiamo realizzare con una regola ? Si, ma al contrario.
Se cerco di aprire wp-login.php e NON mi connetto dall’italia, blocca l’accesso.

Chiaramente è solo un esempio banale
c’è molto altro che si può fare, ma :
a) dovete analizzare l’elenco degli attacchi per un paio di settimane b) caso per caso, dovete fare attenzione a quello che scrivete nelle regole, perchè potreste accidentalmente bloccare l’accesso a parti del sito. E chiaramente se lo fate per un cliente, significa potenzialmente fargli perdere del business, quindi
Fate molti test prima, durante e dopo il rilascio delle regole.
l’opzione nucleare (fare molta attenzione)
Dopo qualche tempo potreste cominciare a notare degli schemi di attacco, perchè certe vulnerabilità sono abbastanza note.
E avete solo 5 regole a disposizione per un dominio con account gratuito…
Beh, queste regole si possono combinare generalmente, ma questo richiede ancora più cautela.
Durante la definizione delle regole è presente un link chiamato “expression editor”.
Queste regole sono sostanzialmente un linguaggio di codifica che permettono di impostare le regole come se fosse una sorta di programmazione.
Per esempio la regola sopra menzionata, può essere espressa in questo modo:
(http.request.uri.path contains "/wp-login.php" and ip.geoip.country ne "IT")
Volendo è possibile aggiungere parametri e poi il sistema si occupa di trasformarli in una sequenza editabile.
(http.request.uri.path contains "wp-") or (http.request.uri.path contains "login") or (http.request.uri.path contains ".git") or (http.request.uri.path contains ".env") or (http.request.uri.path contains ".asp") or (http.request.uri.path contains ".ashx")
si trasforma in

lo ripeto nuovamente: fate molti test
queste regole sono potentissime, ma possono bloccare Google se applicate male.
Queste regole sono “mie” perchè sui miei progetti personali non uso wordpress, quindi posso permettermi di bloccare totalmente le richieste al server che contengono “wp-”.
Per voi potrebbe essere una situazione drasticamente differente!
A parte questo… buon combattimento!
Nothing great was ever achieved without enthusiasm. — Ralph Waldo Emerson
Andrea Scarpetta
Consulente di digital marketing e machine learning per le aziende
Mi occupo di digital marketing dal lontano 2002 e non ho mai smesso di aggiornarmi perchè il mercato me lo impone. Mi occupo di machine learning applicato al marketing dal 2020.